好程序員-千鋒教育旗下高端IT職業教育品牌
官方微信
2021-07-20
好程序員 Java培訓 web前端培訓
在當前數據量激增傳統的時代,不同的業務場景都有大量的業務數據產生,對于這些不斷產生的數據應該如何進行有效地處理,成為當下大多數公司所面臨的問題。企業需要能夠同時支持高吞吐、低延遲、高性能的流處理技術來處理日益增長的數據。
相對于傳統的數據處理模式,流式數據處理則有著更高的處理效率和成本控制。Apache Flink就是近年來在開源社區發展不斷發展的能夠支持同時支持高吞吐、低延遲、高性能分布式處理框架。
Flink在近年來逐步被人們所熟知和使用,其主要原因不僅因為提供同時支持高吞吐、低延遲和exactly-once語義的實時計算能力,同時Flink還提供了基于流式計算引擎處理批量數據的計算能力,真正意義實現了批流統一,同時隨著Alibaba對Blink的開源,極大地增強了Flink對批計算領域的支持。
目前在全球范圍內,越來越多的公司開始使用Flink,在國內比較出名的互聯網公司如Alibaba,美團,滴滴等,都在大規模的使用Flink作為企業的分布式大數據處理引擎。
到底什么Flink?今天圓圓就帶大家認識一下:
一、什么是Flink?
Apache Flink是由Apache軟件基金會開發的開源流處理框架,其核心是用Java和Scala編寫的分布式流數據流引擎。
Flink以數據并行和流水線方式執行任意流數據程序,Flink的流水線運行時系統可以執行批處理和流處理程序。此外,Flink的運行時本身也支持迭代算法的執行。
用圖表示就是這樣的:
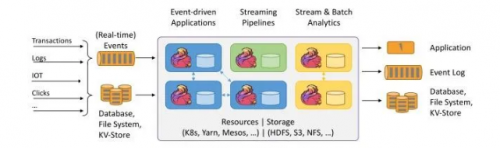
上圖大致可以分為三塊內容:左邊為數據輸入、右邊為數據輸出、中間為Flink數據處理。
Flink支持消息隊列的Events(支持實時的事件)的輸入,上游源源不斷產生數據放入消息隊列,Flink不斷消費、處理消息隊列中的數據,處理完成之后數據寫入下游系統,這個過程是不斷持續的進行。
二、Flink都有哪些優勢?
1.同時支持高吞吐、低延遲、高性能
Flink是一套集高吞吐,低延遲,高性能三者于一身的分布式流式數據處理框架。
非常成熟的計算框架Apache Spark也只能兼顧高吞吐和高性能特性,在Spark Streaming流式計算中無法做到低延遲保障;而Apache Storm只能支持低延遲和高性能特性,但是無法滿足高吞吐的要求。而對于滿足高吞吐,低延遲,高性能這三個目標對分布式流式計算框架是非常重要的。
2.支持事件時間(Event Time)概念
在流式計算領域中,窗口計算的地位舉足輕重,但目前大多數計算框架窗口計算所采用的都是系統時間(Process Time),也是事件傳輸到計算框架處理時,系統主機的當前時間,Flink能夠支持基于事件時間(Event Time)語義的進行窗口計算,就是使用事件產生的時間,這種時間機制使得事件即使無序到達甚至延遲到達,數據流都能夠計算出精確的結果,同時保持了事件原本產生時的在時間維度的特點,而不受網絡傳輸或者計算框架的影響。
3.支持有狀態計算
Flink在1.4版本中實現了狀態管理,所謂狀態就是在流式計算過程中將算子的中間結果數據的保存在內存或者DB中,等下一個事件進入接著從狀態中獲取中間結果進行計算,從而無需基于全部的原始數據統計結果,這種做法極大地提升了系統的性能,同時也降低了計算過程的耗時。
對于數據量非常大且邏輯運算非常復雜的流式運算,基于狀態的流式計算則顯得非常使用。
4.支持高度靈活的窗口(Window)操作
在流處理應用中,數據是連續不斷的,需要通過窗口的方式對流數據進行一定范圍的聚合計算,例如統計在過去的1分鐘內有多少用戶點擊了某一網頁,在這種情況下,我們必須定義一個窗口,用來收集最近一分鐘內的數據,并對這個窗口內的數據再進行計算。
Flink將窗口劃分為基于Time、Count、Session,以及Data-driven等類型的窗口操作,窗口能夠用靈活的觸發條件定制化從而達到對復雜的流傳輸模式的支持,不同的窗口操作應用能夠反饋出真實事件產生的情況,用戶可以定義不同的窗口觸發機制來滿足不同的需求。
5.基于輕量級分布式快照(Snapshot)實現的容錯
Flink能夠分布式運行在上千個節點之上,將一個大型計算的流程拆解成小的計算過程,然后將計算過程分布到單臺并行節點上進行處理。
在任務執行過程中,能夠自動的發現事件處理過程中的錯誤而導致數據不一致的問題,常見的錯誤類型例如:節點宕機,或者網路傳輸問題,或是由于用戶因為升級或修復問題而導致計算服務重啟等。
在這些情況下,通過基于分布式快照技術的Checkpoints,將執行過程中的任務信息進行持久化存儲,一旦任務出現異常宕機,Flink能夠進行任務的自動恢復,從而確保數據在處理過程中的一致性。
6.基于JVM實現獨立的內存管理
內存管理是每套計算框架需要重點考慮的領域,尤其對于計算量比較大的計算場景,數據在內存中該如何進行管理,針對內存管理這塊,Flink實現了自身管理內存的機制,盡可能減少Full GC對系統的影響。
另外通過自定義序列化/反序列化方法將所有的對象轉換成二進制在內存中存儲,降低數據存儲的大小,更加有效的對內存空間進行利用,降低GC所帶來的性能下降或者任務停止的風險,同時提升了分布式處理過數據傳輸的性能。
因此Flink較其他分布式處理的框架則會顯得更加穩定,不會因為JVM GC等問題而導致整個應用宕機的問題。
正是由于Flink的這些優勢,也吸引了眾多的企業參與研發和使用Flink這項技術。
因此,大家也都把Flink稱為:下一代大數據處理框架的標準。
既然Flink在大數據處理中那么重要,那么該如何入門學習呢?
圓圓今天就為大家帶來了《好程序員2020全套Flink教程(共400集)》,教程中除了視頻之外,還配有全套源碼+筆記,讓大家學習無憂!
三、好程序員2020年Flink教程—課程介紹
1.課程內容
本課程涵蓋Flink概念、Flink介紹、初識Flink代碼開發、Flink集群部署&運行時架構、Flink流處理API、Flink Connector、Flink高級特性、Flink window和time操作、Flink Tale API & SQL、Flink CEP等知識點。該套課程深度剖析了時下熱門的流處理框架之Flink ,你值得擁有。
2.通過本課程你可以學到哪些知識?
學完本課程,你可以完全掌握Flink批處理和流處理、掌握時間和窗口計算、掌握Flink常用的Connector、掌握延遲數據處理之WaterMark水位線機制、掌握Flink狀態管理和容錯機制、掌握Flink的部署模式和高可用配置等。
3.適合哪些人學習?
本套課程適合有一定大數據基礎的同學學習。
4.好程序員2021年Flink學習路線
課程目錄
第1章-Flink介紹、初識Flink代碼開發
1.01 講師個人介紹
1.02 Flink課程內容概述
1.03 Flink前世今生
1.04 Flink定義
1.05 Flink在全球的熱度
1.06 Flink在國內企業中的應用
1.07 為什么選擇Flink
1.08 哪些行業需要處理流式數據
1.09 傳統數據處理結構之事務處理
1.10 傳統數據處理結構之分析處理
1.11 Flink中有狀態的流式處理
1.12 流處理演變之Lamda架構
1.13 流處理技術的演變
1.14 Flink的主要特點之事件驅動型應用
1.15 Flink的主要特點之基于流的世界觀
1.16 Flink的主要特點之分層API
1.17 Flink的其他特點
1.18 Flink vs Spark Streaming特點概述
1.19 Flink & Spark Streaming之數據模型以及運行時架構對比說明
1.20 Flink的應用場景之數據分析應用
1.21 Flink的應用場景之數據管道應用
1.22 Flink之前版本(<1.9.0)的架構圖
1.23 Flink當前版本(≥1.9.0)的架構圖
1.24 Flink中的流處理與批處理
1.25 Flink項目相關的maven依賴詳解
1.26 初識Flink代碼開發之pom依賴
1.27 有界流開發業務分解
1.28 有界流開發之代碼輪廓搭建
1.29 有界流開發詳解以及效果演示
1.30 有界流開發總結
第2章-初識Flink代碼開發、Flink集群部署以及運行時架構
2.31 上堂課知識點回顧
2.32 WordCount案例之源在本地目的地在hdfs前期準備
2.33 WordCount案例之源在本地目的地在hdfs核心代碼書寫以及效果演示
2.34 WordCount案例之源在本地目的地在hdfs總結
2.35 WordCount案例之源在hdfs目的地在本地核心代碼書寫以及效果演示
2.36 WordCount案例之源在hdfs目的地在本地總結
2.37 WordCount案例之源在hdfs目的地在hdfs核心代碼書寫以及效果演示
2.38 WordCount案例之源在hdfs目的地在hdfs總結
2.39 WordCount案例之代碼優化以及效果演示
2.40 WordCount案例之代碼優化總結
2.41 無界流之WordCount案例說明
2.42 無界流之WordCount案例源碼以及效果演示
2.43 無界流之WordCount案例總結
2.44 無界流之WordCount案例優化以及效果演示
2.45 無界流之WordCount案例總結
2.46 Flink應用部署模式介紹
2.47 Flink應用部署之local模式實操
2.48 Flink應用部署之local模式實操Ⅱ
2.49 Flink應用部署之local模式實操Ⅲ
2.50 Flink應用部署local模式之命令行方式總結
2.51 Flink應用部署local模式之可視化部署方式說明
2.52 Flink應用部署local模式之可視化部署方式演示
2.53 Flink應用部署local模式之可視化部署方式總結
2.54 Flink應用部署之standalone方式說明
2.55 Flink分布式集群搭建實操
2.56 Flink分布式集群搭建總結
2.57 flink應用部署到Flink分布式集群之命令行方式實操
2.58 flink應用部署到Flink分布式集群之命令行方式總結
2.59 flink應用部署到Flink分布式集群之可視化方式演示
2.60 flink應用部署到Flink分布式集群之可視化方式總結
第3章-Flink集群部署以及運行時架構
3.61 上堂課知識點回顧
3.62 Standalone模式任務調度原理
3.63 Flink Standalone HA說明
3.64 Flink Standalone HA實操
3.65 Flink Standalone HA驗證
3.66 Flink Standalone HA總結1
3.67 Flink Standalone HA總結2
3.68 Flink應用部署模式之Flink On Yarn介紹
3.69 Flink On Yarn兩種具體實現方式之session、per job詳解
3.70 session方式實操
3.71 上午知識點回顧
3.72 將Flink應用部署到session中實操
3.73 將Flink應用部署到session中總結
3.74 session部署方式集群的停止
3.75 Per Job方式介紹
3.76 Per Job方式實操
3.77 Per Job方式總結
3.78 Flink On Yarn內部實現
3.79 Flink On Yarn內部實現之類比說明
3.80 JobManager進程的HA介紹
3.81 JobManager進程的HA介紹
3.82 JobManager進程的HA實操1
3.83 JobManager進程的HA實操2
3.84 JobManager進程的HA最終效果演示
第4章-Flink運行時架構以及Flink流處理API
4.085 上堂課知識點回顧
4.086 Flink On Yarn模式之運行時組件
4.087 Flink運行時組件之作業管理器JobManager
4.088 Flink運行時的組件之任務管理器TaskManager
4.089 Flink運行時的組件之資源管理器ResourceManager
4.090 Flink運行時的組件之分發器Dispatcher
4.091 從高層級的視角詳解任務提交流程
4.092 Flink On Yarn任務提交流程總結
4.093 TaskManager和Slots
4.094 TaskManager和Slots深度剖析
4.095 Flink應用并行度的設置
4.096 程序與數據流
4.097 程序與數據流詳解
4.098 DataFlow中的Oprator與程序中的Transformation關系實操
4.099 ataFlow中的Oprator與程序中的Transformation關系總結
4.100 堂課知識點回顧
4.101 執行圖
4.102 執行圖四層詳解
4.103 并行度
4.104 并行度圖解
4.105 Stream在算子之間傳輸數據的形式
4.106 任務鏈Oprator Chain
4.107 任務鏈Oprator Chain實操以及總結
4.108 任務鏈生成圖解
4.109 使用無界流API進行離線計算實操
4.110 使用無界流API進行離線計算總結
4.111 Flink 流處理API之Enviroment
4.112 DataStream API概述
4.113 DataSet API概述
4.114 DataStream Source API之從集合中讀取數據實操
4.115 DataStream Source API之從集合中讀取數據總結
第5章-Flink流處理API
5.116 上堂課知識點回顧1
5.117 上堂課知識點回顧2
5.118 Source案例之從文件讀取數據實操
5.119 Source案例之從文件讀取數據總結
5.120 以kafka消息隊列中的數據作為來源介紹
5.121 以kafka消息隊列中的數據作為來源案例之前期準備
5.122 以kafka消息隊列中的數據作為Source案例實操
5.123 以kafka消息隊列中的數據作為Source案例效果演示以及總結
5.124 自定義Source介紹
5.125 自定義Source實操之代碼輪廓搭建
5.126 SourceFunction自定義子類核心源碼書寫以及效果演示
5.127 自定義Source案例總結
5.128 DataStream Transformation API之map、flatMap、filter和keyBy介紹
......
第18章-Window和Time操作、CEP
18.379 上堂課知識點回顧Ⅰ
18.380 上堂課知識點回顧Ⅱ
18.381 Watermark總結
18.382 Flink Table API 和 Flink SQL介紹
18.383 Flink Table API使用方式簡介
18.384 Flink Table API簡單案例實操
18.385 Flink Table API簡單案例效果演示以及總結
18.386 給Flink Table API中相應的字段取別名
18.387 使用鏈式編程方式對Flink Table API編程方式進行優化
18.388 Flink Table API的窗口操作案例說明
18.389 Flink Table API的窗口操作案例實操
18.390 Flink Table API窗口操作效果演示以及總結
18.391 Flink Table API中關于groupBy和時間窗口說明
18.392 Flink Table API之toAppendStream和toRetractStream詳解之案例實操
18.393 Flink Table API之toAppendStream和toRetractStream總結
18.394 Flink SQL特點闡述以及使用方式說明
18.395 Flink SQL使用方式案例實操以及效果演示
18.396 Flink SQL使用方式案例總結
18.397 使用Flink SQL API進行窗口操作案例實操以及效果演示
18.398 使用Flink SQL API進行窗口操作案例總結
18.399 使用Flink SQL API實時統計單詞出現的次數案例實操以及總結
18.400 Flink Table API 和Flink SQL總結
18.401 Flink CEP介紹
18.402 非確定有限自動機(NFA)
18.403 Flink CEP Library介紹
18.404 Flink CEP案例介紹
18.405 Flink CEP案例之Event類設計
18.406 Flink CEP案例實操Ⅰ
18.407 Flink CEP案例實操Ⅱ之定制CEP Pattern
18.408 Flink CEP案例實操Ⅲ
18.409 Flink CEP案例最終效果演示
18.410 Flink CEP案例總結
18.411 Flink CEP案例優化
18.412 Flink CEP個體模式的條件介紹
18.413 模式序列和模式檢測
18.414 匹配事件的提取和超時事件的提取說明
18.415 超時事件處理案例實操Ⅰ
18.416 超時事件處理案例實操Ⅱ
18.417 超時事件處理案例總結


 掃碼開啟架構師蛻變之旅 >>
掃碼開啟架構師蛻變之旅 >>
開班時間:2021-04-12(深圳)
開班盛況開班時間:2021-05-17(北京)
開班盛況開班時間:2021-03-22(杭州)
開班盛況開班時間:2021-04-26(北京)
開班盛況開班時間:2021-05-10(北京)
開班盛況開班時間:2021-02-22(北京)
開班盛況開班時間:2021-07-12(北京)
預約報名開班時間:2020-09-21(上海)
開班盛況開班時間:2021-07-12(北京)
預約報名開班時間:2019-07-22(北京)
開班盛況
Copyright 2011-2023 北京千鋒互聯科技有限公司 .All Right
京ICP備12003911號-5
 京公網安備 11010802035720號
京公網安備 11010802035720號













